

[월:] 2026년 02월
-

AI는 다소 과대평가 되거나 다분히 과소평가 되고 있다
링크드인을 켜면 매일같이 장밋빛 환상이 쏟아진다. 클로드나 오픈클로우(OpenClaw)로 하루 만에 프로그램을 만들었다는 둥, 이제 개발은 아이디어 싸움이라는 둥… 하지만 정작 개발 현장에서 마주하는 풍경은 사뭇 다르다. AI에게 뇌를 맡긴 채 ‘개판’으로 내린 지시로 짜인 이상한 코드들, 확장성이라곤 고려하지 않은 하드코딩 수준의 MR을 마주할 때면 이 괴리감은 극에 달한다. AI는 정말 우리를 대체하고 있는가, 아니면 우리는…
-
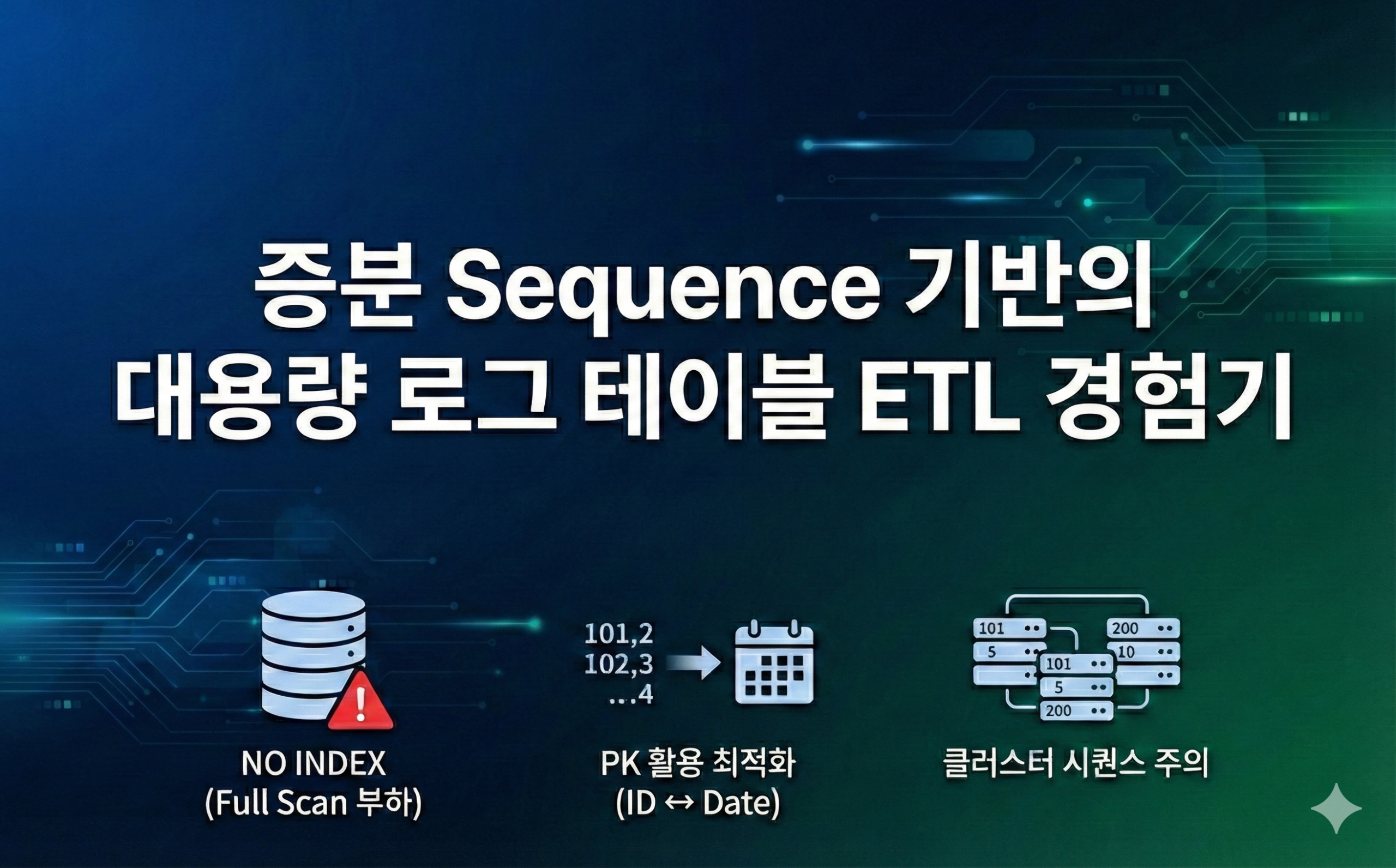
증분 Sequence 기반의 대용량 로그 테이블 ETL 경험기
“로그 테이블 created_at에 인덱스 하나만 걸어주시면 안 될까요?”“테이블 사이즈가 수십 TB인데 인덱스만 TB 단위입니다. 안 됩니다.” 데이터 엔지니어로서 대용량 로그성 데이터를 다루다 보면 필연적으로 마주치는 상황이다. UPDATE 없이 쌓이기만 하는(Append-only) 로그 테이블인데, 너무 거대해서 날짜 컬럼(created_at)에 인덱스조차 걸 수 없는 상황.이 글은 그런 척박한 환경에서 Primary Key(Sequence) 하나만 믿고 고속으로 데이터를 퍼 날랐던 전략과, 그…
-
![[Troubleshooting] Spark가 데이터를 두 번 읽는 방법: JDBC 파티셔닝과 격리 수준의 환장 콜라보](https://goulgoul.kr/wp-content/uploads/2026/02/Gemini_Generated_Image_anw7meanw7meanw7-scaled.png)
[Troubleshooting] Spark가 데이터를 두 번 읽는 방법: JDBC 파티셔닝과 격리 수준의 환장 콜라보
“어제 매출이 왜 2배로 뛰었죠? 마케팅 대박 났나요?”“아뇨… 그럴 리가요…” (등줄기에 땀이 흐른다) 1. 사건의 발단: “데이터가 뻥튀기 됐어요” 어느 평화로운 오전, 분석가님으로부터 메시지가 왔다. 후행 마트 테이블의 집계 수치가 평소보다 훨씬 높게 나온다는 것.확인해 보니 특정 시간대의 데이터가 정확히 중복(Duplicate) 적재되어 있었다. PK가 중복되었으니 당연히 Sum 집계는 뻥튀기될 수밖에. 사용 중인 기술 스택은 AWS…
